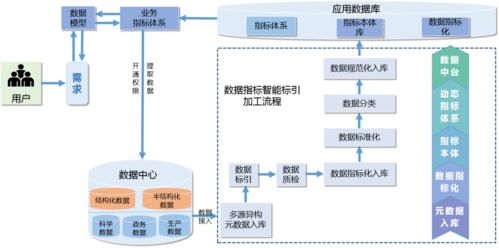
在知網大數據治理工具系統的整體架構中,數據處理是承上啟下的核心環節。本篇將詳細解析該系統的數據處理模塊,包括數據清洗、數據轉換、數據集成、數據脫敏等關鍵功能。
一、數據清洗功能
數據清洗模塊提供智能化的數據質量檢測與修復能力,支持:
- 格式校驗:自動識別數據類型與格式規范,檢測格式錯誤
- 缺失值處理:提供均值填補、眾數填補、刪除記錄等多種處理策略
- 異常值檢測:基于統計方法和機器學習算法識別異常數據
- 重復數據識別:通過相似度計算和規則匹配識別重復記錄
二、數據轉換功能
數據轉換模塊支持多種數據結構的轉換與標準化:
- 格式轉換:支持CSV、JSON、XML等多種數據格式互轉
- 編碼轉換:自動處理字符編碼問題,支持UTF-8、GBK等編碼轉換
- 數據類型轉換:實現數值型、字符型、日期型等數據類型的自動轉換
- 數據標準化:提供歸一化、標準化等數據預處理方法
三、數據集成功能
該模塊實現多源異構數據的無縫集成:
- 數據聯邦:支持跨數據源的聯合查詢與訪問
- ETL處理:提供可視化的ETL流程設計界面
- 實時數據接入:支持Kafka、Flume等流式數據接入
- API集成:提供RESTful API接口,便于系統間數據交換
四、數據脫敏與安全
為確保數據安全合規,系統提供:
- 敏感數據識別:基于規則和機器學習算法自動識別敏感信息
- 脫敏策略:支持掩蓋、替換、泛化等多種脫敏方式
- 權限控制:細粒度的數據訪問權限管理
- 操作審計:完整記錄數據處理操作日志
五、性能優化特性
系統在數據處理性能方面具備以下優勢:
- 分布式計算:基于Spark引擎實現大規模數據并行處理
- 內存計算:采用內存計算技術提升處理效率
- 智能調度:根據數據量和計算復雜度自動優化任務調度
- 緩存機制:建立多級緩存體系,減少重復計算
知網大數據治理工具系統的數據處理模塊,通過上述功能的有機整合,為用戶提供了高效、安全、智能的數據處理解決方案,有效支撐了后續的數據分析和應用環節。系統的可視化操作界面和豐富的API接口,使得數據處理工作更加便捷高效,大大提升了數據治理的整體效率。