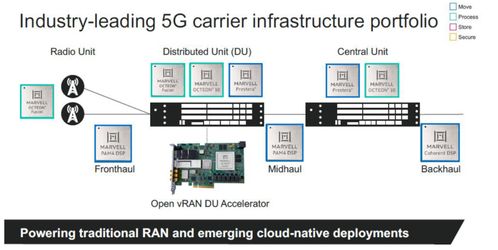
設計模式是軟件工程中解決常見問題的經典方案,其中工廠模式系列在數據處理中發揮著重要作用。它們通過封裝對象創建過程,提高代碼的可維護性、可擴展性和復用性。本文將探討簡單工廠、工廠方法和抽象工廠三種模式在數據處理場景中的應用與區別。
一、簡單工廠模式(Simple Factory)
簡單工廠模式通過一個工廠類統一創建對象,根據傳入參數決定具體產品類型。在數據處理中,它常用于創建不同類型的數據處理器。
應用場景示例:
假設需要處理多種格式的數據(如JSON、XML、CSV),可以定義一個數據處理器接口,并實現不同格式的處理類。通過簡單工廠根據文件擴展名創建對應的處理器:`java
public class DataProcessorFactory {
public static DataProcessor createProcessor(String fileType) {
switch (fileType.toLowerCase()) {
case "json": return new JsonProcessor();
case "xml": return new XmlProcessor();
case "csv": return new CsvProcessor();
default: throw new IllegalArgumentException("Unsupported format");
}
}
}`
優點:客戶端無需關心具體實現,耦合度低。
缺點:新增數據類型需修改工廠類,違反開閉原則。
二、工廠方法模式(Factory Method)
工廠方法模式將對象創建延遲到子類,通過抽象工廠類和產品類實現擴展。
應用場景示例:
在數據處理中,若需要支持動態擴展的數據源(如數據庫、API、文件),可定義抽象工廠和產品接口:`java
public abstract class DataSourceFactory {
public abstract DataProcessor createProcessor();
}
public class DatabaseFactory extends DataSourceFactory {
@Override
public DataProcessor createProcessor() {
return new DatabaseProcessor();
}
}`
優點:符合開閉原則,新增數據源只需添加新工廠類。
缺點:類數量增多,系統復雜度提高。
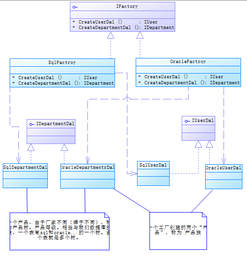
三、抽象工廠模式(Abstract Factory)
抽象工廠模式提供創建一系列相關或依賴對象的接口,無需指定具體類。
應用場景示例:
在復雜數據處理系統中,可能需要同時創建數據讀取器和寫入器(如MySQL讀取器與寫入器、Redis讀取器與寫入器)。抽象工廠可以統一管理這些相關對象:`java
public interface DataFactory {
DataReader createReader();
DataWriter createWriter();
}
public class MySQLFactory implements DataFactory {
@Override
public DataReader createReader() {
return new MySQLReader();
}
@Override
public DataWriter createWriter() {
return new MySQLWriter();
}
}`
優點:保證產品家族的兼容性,便于切換整個產品系列。
缺點:新增產品類型需修改所有工廠類,擴展性較差。
總結與對比
- 簡單工廠:適用于產品類型固定、變化較少的場景,如基礎數據格式處理。
- 工廠方法:適用于需要靈活擴展產品類型的場景,如多數據源支持。
- 抽象工廠:適用于產品家族復雜、需保證相關對象兼容性的場景,如完整的數據處理流水線。
在數據處理中,合理選擇工廠模式能顯著提升代碼質量。簡單工廠適合快速開發,工廠方法支持擴展,抽象工廠則適用于大型系統架構。開發者應根據具體需求權衡其優缺點,實現高效、可維護的數據處理方案。