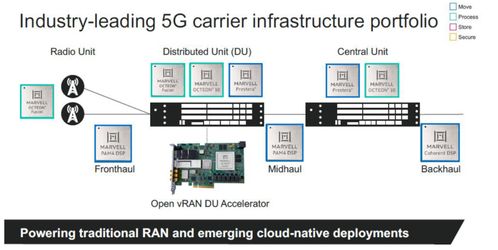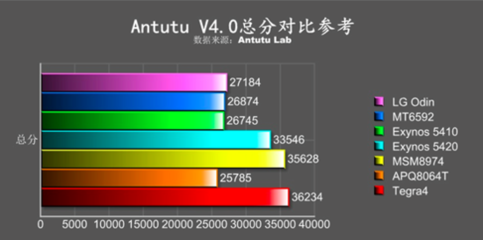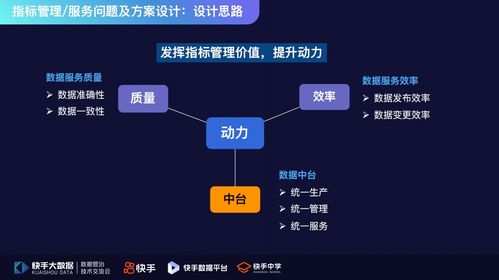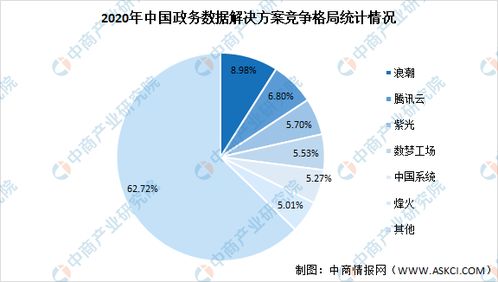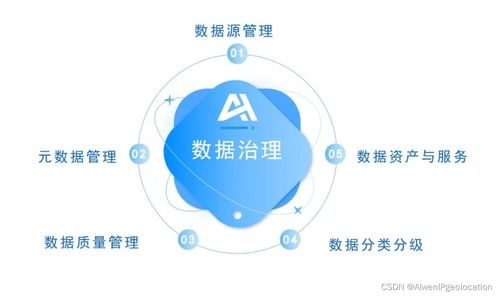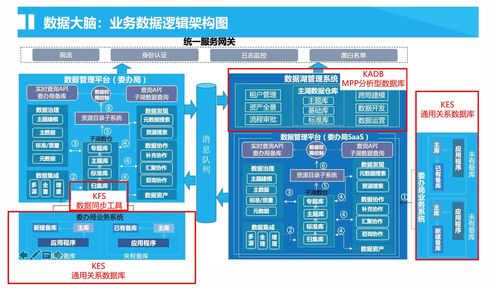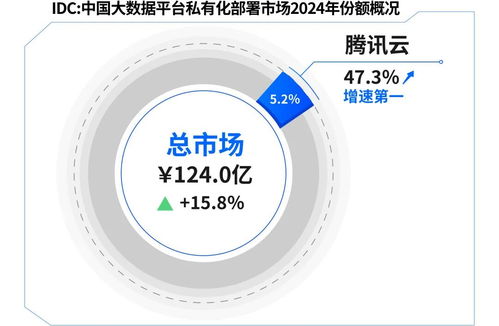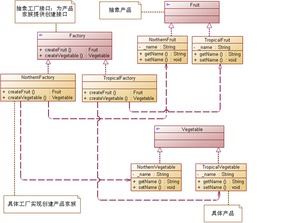
在數據分析領域,高效處理復雜數據源是關鍵挑戰。抽象工廠模式作為工廠模式的進階形式,為解決這一問題提供了優雅方案。
抽象工廠模式核心概念
抽象工廠模式通過創建相關或依賴對象的家族,而無需指定具體類。在數據分析場景中,這意味著我們可以創建統一的數據處理管道,適配不同數據源(如CSV、數據庫、API等)。
Python實現示例
假設我們需要處理多種數據格式,可以通過抽象工廠實現:`python
from abc import ABC, abstractmethod
class DataProcessorFactory(ABC):
@abstractmethod
def createreader(self):
pass
@abstractmethod
def createcleaner(self):
pass
@abstractmethod
def create_analyzer(self):
pass
class CSVProcessorFactory(DataProcessorFactory):
def createreader(self):
return CSVReader()
def createcleaner(self):
return CSVCleaner()
def create_analyzer(self):
return CSVAnalyzer()`
在DataGuru社區的實際應用
DataGuru作為專業數據分析社區,推薦以下實踐:
- 數據源擴展性:新數據源只需實現對應工廠類
- 代碼復用:統一接口確保數據處理邏輯一致
- 維護便捷:修改特定數據源處理邏輯不影響其他組件
數據處理流程優化
通過抽象工廠模式,數據分析項目能夠:
- 降低模塊間耦合度
- 提高代碼可測試性
- 支持動態數據源切換
- 便于團隊協作開發
在實際項目中,結合pandas、numpy等庫,抽象工廠模式顯著提升了數據處理管道的靈活性和可維護性,是數據分析工程師值得掌握的設計模式。