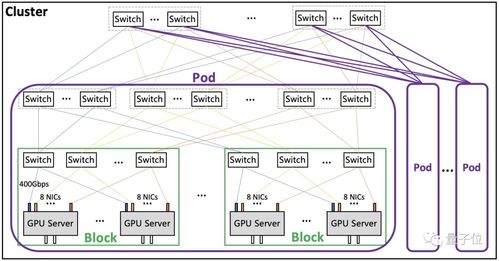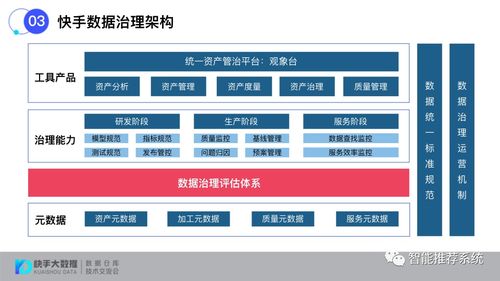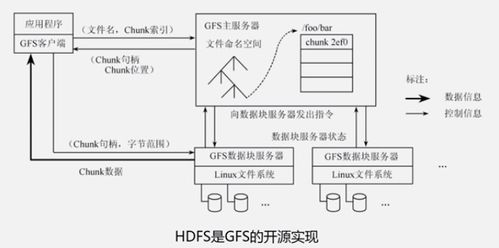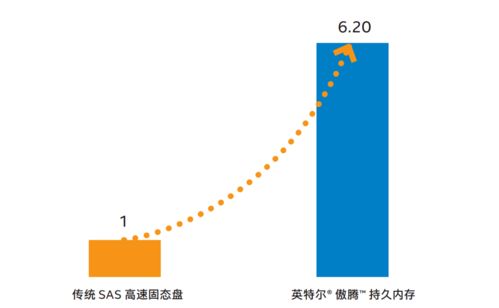
在智能制造的大潮中,企業面臨著海量實時數據處理的挑戰。數據源多、頻率高、種類雜,如何快速、準確地處理這些數據,成為企業數字化轉型的關鍵。有一家智能制造企業通過創新實踐,成功克服了這些難題,其經驗值得行業借鑒。
這家企業首先構建了統一的實時數據處理平臺,整合了生產線、物聯網設備和用戶反饋等多源數據。通過部署高性能流處理技術,如Apache Kafka和Flink,平臺能夠實時接收和分析數據流,實現毫秒級響應。企業將邊緣計算與云計算結合,在數據源頭進行初步過濾和聚合,減輕了中心服務器的負擔,提高了整體處理效率。
為了應對數據質量不穩定的問題,企業引入了自動化的數據清洗和校驗機制。通過機器學習算法,系統能夠實時識別并修正異常數據,確保輸入信息的準確性。企業還建立了靈活的數據存儲架構,支持結構化和非結構化數據的混合處理,滿足不同業務場景的需求。
在數據應用層面,該企業將實時處理結果與生產流程深度融合。例如,通過實時監控設備運行狀態,系統能夠預測潛在的故障,并自動觸發維護任務,減少了停機時間。銷售和庫存數據實時聯動,幫助企業優化供應鏈,降低了庫存成本。
這一做法不僅提升了生產效率,還增強了企業的敏捷性。據統計,實施后,企業的數據延遲降低了80%,決策響應速度提高了50%。這為其他智能制造企業提供了寶貴經驗:在實時數據處理中,技術集成、自動化和業務整合缺一不可。隨著5G和AI技術的普及,類似實踐將推動整個行業向更智能、高效的方向發展。