在信息技術飛速發展的今天,我們已全面邁入大數據時代。海量、多樣、高速的數據如潮水般涌來,深刻改變著社會生產、商業運營與科學研究的面貌。數據的價值并非自然顯現,其關鍵在于“處理”——如何從龐雜的數據洪流中提取出有意義的洞察,已成為這個時代的核心命題。
數據處理,指的是對原始數據進行收集、清洗、存儲、分析和可視化的全過程。在大數據語境下,這一過程面臨著前所未有的挑戰與機遇。傳統的數據庫與處理工具在應對PB甚至EB級別的非結構化數據時往往力不從心,這催生了以Hadoop、Spark為代表的大數據技術生態的蓬勃發展。這些分布式計算框架,通過將任務分解到成百上千臺普通服務器上并行處理,實現了對海量數據的高效分析。
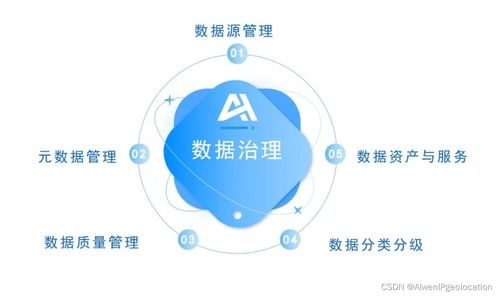
數據處理流程的起點是數據采集與集成。來自傳感器、社交網絡、交易記錄、物聯網設備等多元異構的數據源,需要通過數據管道進行實時或批量的匯聚。緊接著是至關重要的數據清洗與預處理階段,即“數據治理”。原始數據常包含噪音、缺失值與不一致性,必須經過過濾、去重、轉換與標準化,才能轉化為高質量的、可供分析的數據資產,正所謂“垃圾進,垃圾出”。
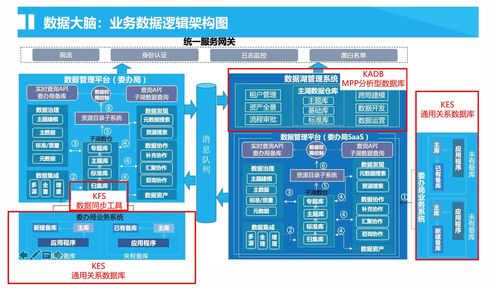
數據存儲與管理構成了處理的基石。大數據存儲已從單一的關系型數據庫,演變為包括NoSQL數據庫(如MongoDB、Cassandra)、分布式文件系統(如HDFS)、以及新興的數據湖架構在內的多元化體系。這些技術旨在以更低的成本、更高的可擴展性來存儲結構、半結構及非結構化數據。
數據分析與挖掘是釋放數據價值的核心環節。這既包括傳統的描述性分析(發生了什么),也涵蓋更深入的診斷性分析(為何發生)、預測性分析(將會發生什么)以及指導行動的規范性分析。機器學習與人工智能算法的深度融合,使得從數據中發現復雜模式、預測趨勢乃至實現自動化決策成為可能。例如,推薦系統通過處理用戶行為數據,實現個性化服務;城市大腦通過處理交通流量數據,優化信號燈配時。
數據可視化與呈現則是連接數據洞察與決策者的橋梁。通過圖表、儀表盤甚至交互式三維圖像,將分析結果直觀、易懂地傳達出去,助力管理者快速把握態勢,做出數據驅動的科學決策。
大數據處理并非純粹的技術問題。隨著數據規模擴大,隱私保護、數據安全與倫理問題日益凸顯。如何在利用數據與保護個人權益之間取得平衡,是全社會必須面對的課題。對處理結果的解讀仍需人類的專業知識和批判性思維,避免陷入“數據偏見”的陷阱。
數據處理技術將繼續向實時化、智能化、云原生化方向演進。邊緣計算將處理任務推向數據產生的源頭以降低延遲;增強分析(Augmented Analytics)將更多地借助AI自動化數據分析流程;而算力與算法的持續進步,將讓我們能夠處理更復雜的問題,從浩瀚的數據星海中,更精準地導航出價值的航道。
大數據時代,數據處理是駕馭數字洪流的引擎。它是一門融合了計算機科學、統計學與領域知識的藝術,其發展不僅推動著技術進步,更在重塑我們理解世界與創造價值的方式。只有構建起高效、智能且負責任的數據處理能力,我們才能真正將數據轉化為這個時代的“新石油”,驅動社會邁向更加智慧的未來。